Following best practices for managing your research data can ensure it will be available to other researchers in the long term. Not all of these suggested guidelines will always apply to every discipline or project. Overall, however, these guidelines will streamline your data management activities and help prevent data loss.
Click images to view them larger.
File Structures
Choose a consistent organizational structure for all of your project folders. Although it may seem obvious, thinking about the structure of your folders and planning effectively makes navigation much easier. Minimize the number of clicks necessary to reach files. In conjunction with a consistent file naming convention, an efficient structure saves a lot of time.
Descriptions of hierarchical and tag-based methods are adapted from those presented by MIT Libraries.
Option 1: Hierachical Method
A hierarchical structure is a very common model for file organization, shared by most operating systems (i.e., Windows, Mac, etc.). Folders are nested within subfolders. The hierarchy is much like a traditional outline, and it can be helpful to sketch out your hierarchy before creating it. See Figure 1 for an example of a basic effective folder hierarchy.
Guidelines:
- Be consistent.
- Structure your hierarchy logically. Follow the logic that makes the most sense for your project.
- Keep folders and subfolders separate to reduce overlap. However, don't make an excessive number of subfolders (Figure 2).
- Keep subfolder categories narrow to restrict the number of files in each. See Figure 3 for a subfolder that is too large.
- Your Desktop is meant to be temporary storage. Never keep files there for longer than absolutely necessary.
- When naming folders, think about information you might want when looking up files.
 Figure 1
Figure 1
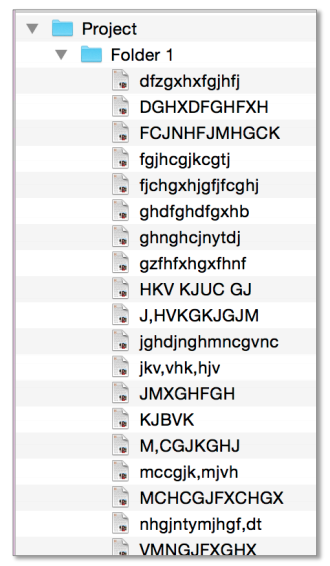 Figure 2
Figure 2
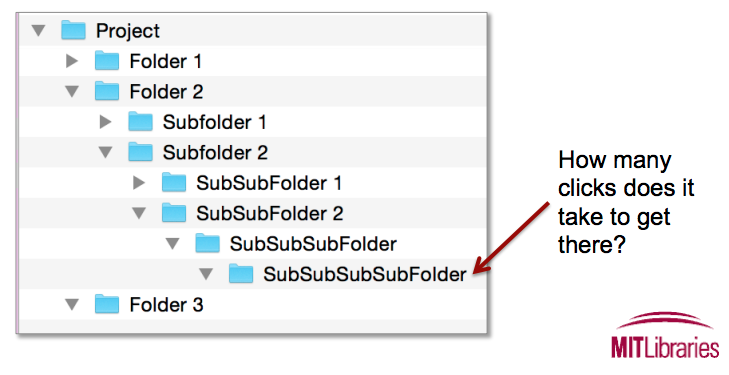 Figure 3
Figure 3
Pros:
- Familiar and widely-used.
- Good at representing the nested structure of information.
- Similar items can be stored together.
- Subfolders can be treated as task lists.
Cons:
- Categories are inherently discrete and can result in forced separation.
- Can be time-consuming to set up or reorganize.
- Hard to find a good balance between breadth and depth.
Examples:
"Lost in the Data Jungle: A Case Study for Organizing, Publishing, & Preserving Research Data": Poster describing a project at the University of Iowa involving a folder organization scheme.
Option 2: Tag-Based Method
If you have ever used a hashtag on Twitter, Instagram, or Facebook, you have used a tag to classify information. If you have ever searched for a hashtag, you've retrieved tagged data. In a similar way, it is possible to use tags to organize your files. Ideally, you should decide on a set of tags to use at the beginning of the project and use consistent tags throughout; if you use too many tags (for instance, some files are #dog, some are #goldenretriever but NOT #dog, and so on), it will be virtually impossible to find your files. On the other hand, if you use too few tags (for instance, all your files are simply tagged #file), the tag no longer yields any useful information. Much like hierarchical methods of file organization, the key is to find a balance.
Figure 4 is an example of the rich tagging system that is part of the Mac operating system. Tags are not an inherent part of most operating systems by nature, but many OSes are beginning to incorporate them, and there are a number of external programs available for tagging files as well. You may already be using tags to organize your email and photos. Online storage like Box (which provides unlimited storage to those with UC Merced logins) also includes tagging abilities (Figure 5). Social media networks like Twitter often use tags to organize information as well (Figure 6).
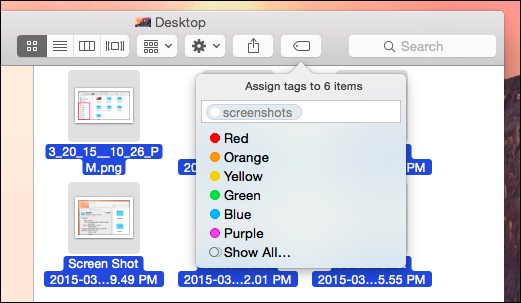 Figure 4
Figure 4
 Figure 5
Figure 5
 Figure 6
Figure 6
Programs for tagging files include, but are not limited to, the following. Most of these programs are designed for Unix or Windows, since the Macintosh OS has built-in tagging functionality.
- Tagsistant (Unix, free)
- Tabbles (Windows, free w/ limited features)
- TMSU (Unix, Windows, free)
Pros:
- Items can be in more than one category at once without taking up extra space.
- Can be easier to set up and to combine during collaborations.
Cons
- Most operating systems don't store files this way -- difficult to represent the structure of organization.
- Typically, you must tag every file when you first acquire them to find them again easily.
Examples:
"Designing better file organization around tags, not hierarchies" is a blog post that thoroughly explains the differences between hierarchical and tag-based organization.
A dissertation by Shanshan Ma at Drexel University assesses users' behavior and preferences using hierarchical and tag-based file organization systems.
File Naming
Establishing a consistent file naming convention early in your project and maintaining that convention throughout is an underrated but incredibly useful practice. Without a convention, it is easy to end up with a lot of files whose names tell you nothing about their contents -- this situation can require a lot of time and effort to locate a single file and can make it near-impossible to find things.
A good naming convention should provide sufficient context for a file; file names should be succinct but informative. You can also use the names of your files to keep track of versions; that is, each time you make a significant change to a file, or a large number of minor changes, you can save the file and give it a new version number. Use ordinal numbers (i.e., 1, 2, 3) for major version changes and add either a decimal (1.1, 1.2, 1.3, etc.) or a letter (1a, 1b, 1c, etc.) for minor version changes. Avoid imprecise labels like "Final" and "Draft."
Programs or applications will almost never provide a good file name automatically. It is good practice to get into the habit of renaming all your files as soon as you create them.
If you work in a large laboratory environment, or in a collaborative setting where you are not the only one working with a set of files, all researchers should be aware of the file naming convention.
Guidelines
- Be consistent!
- Determine a file naming convention before you gather data.
- Limit file names to 32 characters or less (usually less). Keep it short, but make sure to provide all necessary information. If you use abbreviations, define them in a README file (and keep the README file linked to the files it describes).
- With sequential numbering (e.g., 1, 2, 3, etc.), use leading zeros to accommodate multi-digit versions. For example, use 01-10 for 1-10, 001-100 for 1-100, and so on.
- Avoid special characters like & , * % # ; ( ) ! @ $ ^ ~ ' { } [ ] ? < >
- Use underscores _ rather than spaces!
- Use descriptive names that document the important aspects of your project. These can differ across projects. Put the most important information first.
- Keep names easy to read (and consider case sensitivity).
- Use a consistent date and time convention. For dates, YYYYMMDD will result in your files being sorted chronologically.
File Renaming
In a perfect world, you would be able to maintain a file naming convention from the very start of a project and never need to make a change. However, you may find that you need to add or remove information from your file names or make other changes. You have two options:
- Rename each file manually, or
- Use a program capable of renaming files in batches
There are several batch renaming programs available. They include, but are not limited to:
- Bulk Rename Utility (Windows, free)
- Total Commander (Windows, free)
- Renamer (MacOS, $20+)
- PSRenamer (MacOS, Windows, Linux, free)
Examples
The University of Edinburgh provides an excellent, comprehensive (yet easy to follow) list of 13 rules for file naming conventions, with examples and explanations.
A case study of file naming problems by Stanford Libraries.
An example of file naming done well by Stanford Libraries.
Figures 7, 8, and 9 are humorous (and accurate) representations of the problems that can be avoided with good file organization:
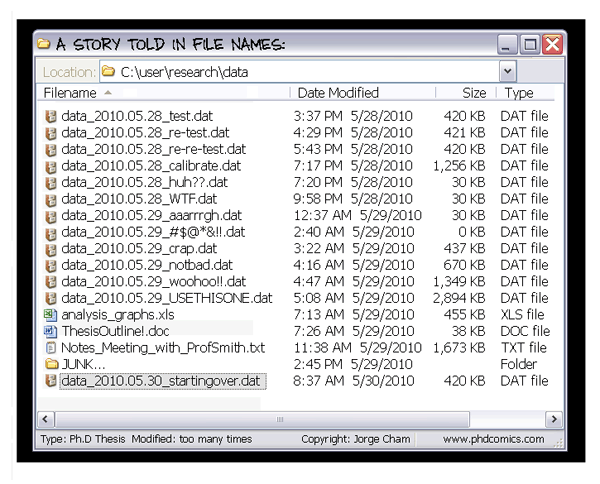 Figure 7
Figure 7
 Figure 8
Figure 8
 Figure 9
Figure 9
File Formats
The best file formats for research data are non-proprietary, "lossless," and unencrypted/uncompiled.
Researchers may sometimes encounter situations where they absolutely must use a problematic file format. In this case, they should make every possible effort to provide a backup version of the file in a different format. They should also provide documentation explaining how to use the problematic format.
Non-Proprietary
If the program that created a file is the only option for reading or accessing the file, the file format is proprietary or not open. To help ensure that your data and files are accessible by a wide range of users for a long time, choose open, non-proprietary formats whenver possible. With proprietary formats, if the original software becomes unavailable or ceases to function, the files are lost.
Non-proprietary, or open, file formats are ones where the dsecription and/or development of the format are open to the public; they often can be opened by multiple software programs. Open formats are often community-maintained.
"Lossless"
Some file formats compress the information in files. This can be useful because the files take up less disk space. However, for many such formats, the compression causes data from the file to be lost. These formats are "lossy." Formats that can compress files without losing any information are "lossless" and retain the original details of the data.
A "lossless" file that has been compressed can be completely restored to its original state, unchanged. A "lossy" file will be compromised in quality due to the deletion of some information.
Unencrypted/Uncompiled
Encrypting or password-locking a file may improve security, but if the encryption key or password is ever lost, the data in the file may also be lost.
Uncompiled source code is easier to re-use and is more likely to last a long time since it can be compiled on a range of architectures/platforms.
Guidelines
Here is a list of some non-proprietary file formats that are generally preferred for different types of files:
- Containers: TAR, GZIP, ZIP
- Databases: XML, CSV
- Geospatial: SHP, DBF, GeoTIFF, NetCDF
- Moving images: MOV, MPEG, AVI, MXF
- Sounds: WAVE, AIFF, MP3, MXF
- Statistics: ASCII, DTA, POR, SAS, SAV, R
- Still images: TIFF, JPEG 2000, PDF, PNG, GIF, BMP
- Tabular data: CSV
- Text: XML, PDF/A, HTML, ASCII, UTF-8
- Web archive: WARC
The Library of Congress' Sustainability of Digital Formats and Recommended Format Specifications provide more extensive information on formats, including guidance for preserving data sets, geospatial data, and web archives.
Examples
A case study of problems that can arise when researchers don't use non-proprietary file formats, by Stanford Libraries.
A detailed table of some most commonly used file formats, compiled by Utah State University (PDF version available at link).
The Australian National Data Service provides an extensive guide to choosing file formats.
Figure 10 is an XKCD infographic/comic about file decay over time.
 Figure 10
Figure 10