Metadata
Definition
Metadata are "data about data" or "data in context." They are pieces of information that provide context for data. Having metadata helps when researchers re-analyze their own data, use other people's data, use existing data for a different project, or collaborate with others. Metadata is becoming increasingly important as the culture of data sharing spreads, although it's important to remember that metadata makes it easier for you to use your own data too. When documenting your research data, ask yourself if it passes the "Ward test" -- that is, if you disappeared, would someone else be able to access, interpret, and analyze your data? If the answer is "No," you should improve your documentation and metadata.
In relation to research data, the term is relatively new (since the mid-1990s), but the concept or construct of metadata is as old as our organization of information. A card catalog, like that in Figure 1, is a classic example:
 Figure 1
Figure 1
Beyond card catalogs, however, metadata is present in many aspects of our lives. We use metadata often without even realizing it. For example, most modern-day cameras, like those in smartphones, record metadata like date, time, settings, and location when photos are taken (Figure 2). The cover of a book is metadata that provides context about its contents (Figure 3). (Dataedo presents details about these and other examples.) When you browse your iTunes or Spotify music library for a song, you are browsing metadata (Figure 4).
 Figure 2
Figure 2
 Figure 3
Figure 3
Figure 3
Creating metadata for your research projects and data leads to increased accessibility, helps data retain its context, accommodates version control (through distinguishing multiple versions), and can satisfy the legal requirements of repositories and funders. Quality metadata also makes data easier to preserve and more persistent over time.
When you create metadata for a piece of data -- whether that data be code, a paper, images, spreadsheets, et cetera -- it can help to answer the following questions:
- Who created the data?
- What does the data file contain?
- When were the data generated?
- Where were the data generated?
- Why were the data generated?
- How were the data generated?
Figure __ shows some of the many possible categories of information that metadata can encompass. Individual choices can vary from project to project; the key is to ensure that enough information is provided to create context for the data.
Figure 1
Metadata Standards
Think about something as simple as writing the date at the top of a page. How would you write February 6th, 2019? You could write it just like that -- February 6th, 2019 -- or 02/06/2019, or 2/6/19, or even 06/02/2019, and the list continues. However, without a standard date format of some kind, one person might read 06/02/2019 as June 2nd. If you're recording dates and you don't clarify which format you're using, you've added a frustrating element of ambiguity. And that's to say nothing of the problematic date formats in Excel, which Christie, a quantitative ecologist, describes in detail.
Even naming formats have standards. Take the following sequence of names: Au,Vickie Shuet Fong; Vickie Au; Backman,Kimberly J.; Kimberly Backman; Smith, John (John); JSMITH. Imagine searching a directory of similar names, all without a consistent format.
For frustrating examples of poor metadata standards (or no standards), try searching Twitter for "#otherpeoplesdata." Figures __ and __ are two examples.
Figure 2
Figure 3
It is important to have consistent standards within labs and collaborators, but the choice of these specific standards can vary. When you are ready to deposit your data set in a repository for archiving and/or sharing, however, it is important to document your data in a way that is easily understandable to other researchers and that is computer-accessible (so people can search for your data set).
Metadata standards exist to create consistency across research documentation.
There are several "discipline agnostic" metadata standards that researchers can choose. They include DataCite, Project Open Data, and the Data Documentation Initiative (DDI). Standards like these can generally be applied to data in almost any discipline.
Specific disciplines often have their own popular sets of metadata standards. The Digital Curation Center (DCC) maintains a directory of standards that can be browsed by discipline. The Research Data Alliance (RDA) offers a community-maintained directory that is updated more frequently.
Finally, the choice of repository sometimes determines the metadata schema. For instance, Dash uses the discipline-agnostic DataCite schema by default. Discipline-specific repositories may use others.
This infographic provides a quick visual overview of different metadata standards by discipline:
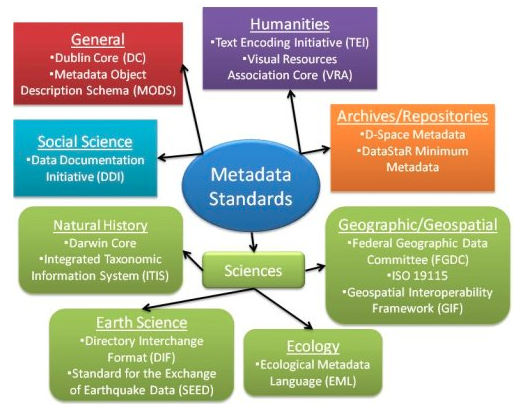
Recording Metadata
When you create a data management plan, make sure to consider who will be responsible for each aspect of the process. This includes creation and maintenance of metadata. It is crucial to remember that metadata must be linked to the data it references. If your metadata becomes separated from the data or files it references, it is useless. Therefore, it is worthwhile for someone to maintain the metadata over time.
Depending on the type of metadata, the choice of recording method and delegation of responsibilities can vary. Even file name conventions typically contain metadata such as version number, etc. -- in that case, whoever saves the file may be responsible for naming. Local documentation, like codebooks and data dictionaries, might be maintained by one or two researchers. Add link to heading.
For some data, recording all relevant metadata manually may be impractical. For these cases, many free tools exist to automate aspects of metadata creation.
Stanford Libraries provides brief descriptions of several tools, along with download links and installation instructions. They also offer a feature comparison chart of these tools.
The Digital Curation Center (DCC) hosts a database of metadata tools and links.
Resources
Penn State's Data Management Plan Tutorial walks through the process of metadata creation with examples
The Getty's free eBook, Introduction to Metadata
Stanford Library's case study of metadata creation for weather data
Documentation
If your data is intended for local use -- meaning that it will only be used by you and your co-authors, labmates, or collaborators -- it doesn't matter what standard(s) you use, as long as they are consistent. The following are some examples of local data documentation that you can immediately implement with your own projects -- that, in fact, you may already be using without realizing! You can (and should) also include this documentation when publishing your data in a repository or archive.
Laboratory or Field Notebooks
These are, as the name implies, physical (analog) or digital notebooks in which researchers document information that is relevant to their research process. Maintaining a notebook means that each researcher is able to localize all their relevant information in one place; it encourages thoughtful work; and it enables other researchers to pick up and continue a line of research if necessary.
Although many researchers do still keep some form of analog notebook(s), there are a number of benefits to digital notebooks. Some of the most popular note-taking software programs include:
- SciNote
- OneNote
- Evernote
- Jupyter
Best practices for maintaining an effective lab notebook include dating each entry in a consistent format, listing names and contact information of collaborators, keeping notes from important meetings or discussions, and justifying methods and data source(s). Researchers should also note any corrections, calculations (with units), file names/locations, and the locations of any physical materials.
Resources
How to Start -- and Keep -- a Laboratory Notebook: Policy and Practical Guidelines, from the ipHandbook of Best Practices
Tips for Maintaining a Laboratory Notebook by Colin Purrington
Matrix of Comparisons for Electronic Lab Notebooks by Harvard Library
Codebook
A set of codes, definitions, and examples often used as a guide to provide context for and help analyze survey data
- Essential for analyzing qualitative research
- Contains the text of survey questions
- Often also contains lists of possible responses for survey questions
- Level of detail is up to the user, but generally, the more specificity, the better
If your research involves administering surveys, you may use a codebook to ease interpretation and increase accessibility of the survey results. If you download an archived data file, that file often comes with some version of a codebook which explains each variable and its possible values.
This is a fairly thorough "Codebook Cookbook" that guides researchers through creating codebooks, and this is a similar cookbook that approaches codebook creation through R. Survey software, like Qualtrics and SurveyMonkey, often allow users to export a created survey as a text file, which can function as a codebook. For Qualtrics, the instructions are here. For SPSS users, here are instructions for you to create simple or more detailed codebooks based on an SPSS datafile.
Example Codebooks
A questionnaire on quality of work life
Canadian National Household Survey (2011)
United States Congressional Survey (1975)
Additional examples in varying formats
Data Dictionary
Example of a data dictionary from the Open Science Foundation (OSF). Click to enlarge.
- Similar to a codebook, but applies to data of any kind in spreadsheets, not only to surveys
- Explains what all the variable names and values in a spreadsheet actually mean
- A separate spreadsheet file in a non-proprietary format that associates all variable names/column headings with necessary data
This is a short (6:30) video explaining the concept and construction of data dictionaries, produced by the University of Wisconsin Data Services.
This blog post delves into the creation of data dictionaries. In general, however, a data dictionary usually contains some variation of the following columns:
- Variable name
- Variable meaning
- Variable units
- Variable format
- Variable coding values and meanings
- Any known issues with the data (systematic errors, missing values, etc.)
- Relationships among the variables
- Null value indicator (what value[s] represent missing data)
- Any other information necessary to better understand the data
For a blank data dictionary template that you can download and customize as necessary, go here.
The Smithsonian suggests some best practices for maintenance of data dictionaries here.
README File
- Like the title implies -- a file that users of your data are intended to read first, which explains all the information users need to know to understand your data
- Make sure that whatever file naming convention you use associates each README file with the file or files that it references
- Use a plain text file or other non-proprietary format to create it and format it clearly
- If you use multiple READMEs, keep the format consistent across them
- Use standard date, time, and name formats within READMEs
A brief overview of recommended README file content:
- Names and contact info for all personnel involved
- Date
- Short description of the data contained in each file
- List of all files (including relationships between them)
- For tabular data, full names and definitions of column headings
- Units of measurement
- Any specialized abbreviations, codes, or symbols used
- Copyrights/licensing information
- Funding sources
For more extensive information about creating README files, go here. This file is an example README template that you can download and customize to meet your needs.
Some data repositories may either require or recommend that you upload README files along with your data. UC Dash, for example, does not currently preserve the hierarchical structure of files and strongly recommends a README.
Examples of datasets in repositories accompanied by READMEs: Paleosol data from Kenya deposited in UO Scholars' Bank; clinical trial mandatory reporting study data deposited in Dryad; comparative analysis of fruit and seed adaptations deposited in Dryad.
These three types of local data documentation -- codebooks, data dictionaries, and README files -- are crucial. They provide context not only for you, the researcher, in the future but also for anyone else who may ever need or want to use your data for any reason. Using other people's data can be either a breeze or a huge headache depending on the quality of the documentation.